高可用性
高可用性
当用户启用并且正确地配置Greenplum高可用特性时,Greenplum数据库支持高度可用的、容错的数据库服务。要保证所要求的服务水平,每一个组件都必须有一个可在它失效时取代它的后备。
磁盘存储
通过Greenplum数据库的“shared-nothing” MPP架构,Master主机和Segment主机每个都拥有其独占的内存和磁盘存储,并且每一个Master或者Segment实例都有其自身的独立的数据目录。为了可靠性和高性能,Pivotal推荐带有8到24个磁盘的硬件RAID存储方案。使用RAID 5(或6)时更多的磁盘能够提升I/O吞吐,因为条带会增加并行的磁盘I/O。有一个失效磁盘时,RAID控制器能够继续工作,因为它在每个磁盘上都保存了校验数据,这样它能够重构阵列中任何失效磁盘上的数据。如果配置了热后备(或者一种用新磁盘替换失效磁盘的操作器),控制器能够自动重建失效磁盘。
RAID 1 就是镜像磁盘,因此如果一块磁盘失效,一个替代品就能立刻可用,并且能提供与失效前同等的性能。对于RAID 5,每一个对失效阵列成员上数据的I/O都必须从其余的活动驱动器上的数据重构出来,直至替代磁盘被重建完,因此会有一些临时性的性能退化。如果Greenplum的Master和Segment都有镜像,用户可以在重建期间把受影响的Greenplum实例切换到它们的镜像上,这样可以维持可接受的性能。
RAID磁盘阵列仍然可能会出现单点失效,例如整个RAID卷失效。在硬件级别上,用户可以通过镜像阵列、使用主机操作系统镜像或者RAID控制器镜像(如果支持)来防止磁盘阵列失效。
有必要定期监视每台Segment主机上可用的磁盘空间。查询gptoolkit方案中的gp_disk_free外部表可以查看Segment上可用的磁盘空间。这个视图会运行Linux的df命令。在执行消耗大量磁盘的操作(例如拷贝大型表)之前,一定要检查是否有足够的磁盘空间。
请见Greenplum数据库参考指南中的gp_toolkit.gp_disk_free。
最佳实践
- 使用带有8到24个磁盘的硬件RAID存储方案。
- 使用RAID 1、5或6,这样磁盘阵列能容忍一个失效磁盘。
- 在磁盘阵列中配置一个热后备以允许在检测到磁盘失效时自动开始重建。
- 通过镜像RAID卷防止整个磁盘阵列的失效和重建期间的退化。
- 定期监控磁盘利用并且在需要时增加额外的空间。
- 监控Segment倾斜以确保数据被均匀地分布并且在所有Segment上存储被均匀地消耗。
Master镜像
Greenplum数据库的Master实例是客户端访问系统的单点。Master实例存储全局系统目录,也就是存储有关数据库实例的元数据的系统表集合,但是它不存储用户数据。如果未被镜像的Master实例失效或者变得不可访问,由于系统的入口点失去,Greenplum实例实际上就会变成离线。由于这一原因,如果主Master失效,一个后备的Master必须准备好接手。
Master镜像使用两个进程将镜像与Master同步,一个发送者位于活动Master主机上,而一个接收者位于镜像主机上。随着更改被应用于Master的系统目录上,活动的Master会将它的预写式日志(WAL)流式传送到镜像,这样应用于Master上的每一个事务都会被应用在镜像上。
镜像是一台温备。如果主要的Master失效,要切换到后备Master需要管理员用户在后备主机上运行gpactivatestandby工具,这样它才会开始接受客户端连接。客户端必须重新连接到新的Master,并且会丢失在主Master失效时还未被提交的任何工作。
更多信息请见Greenplum数据库管理员指南中的“启用高可用特性”。
最佳实践
- 设置一个后备Master实例——镜像——在主要Master失效时接手。
- 后备可以位于同一或者不同主机上,但是最佳实践是把它放在不同于主Master的不同主机上,这样可以防止主机失效。
- 规划好当失效发生时如何把客户端切换到新的Master实例,例如通过更新DNS中的Master地址。
- 设置监控,当主Master失效时在系统监控应用中发送通知或者通过邮件通知。
Segment镜像
Greenplum数据库的每一个Segment实例都在Master实例的协调下存储和管理数据库数据的一部分。如果任何未镜像的Segment失效,数据库可能不得不被关闭并且恢复,并且在最近备份之后发生的事务可能会丢失。因此,镜像Segment是高可用方案的一个不可缺少的元素。
-
在事务被提交之前,事务提交日志被从主Segment复制到镜像Segment。这会确保当镜像被激活时,主Segment上最后一个成功的事务所作的更改会出现在镜像上。当镜像被激活时,日志中的事务会被应用到镜像中的表上。
-
第二种,Segment镜像使用物理文件复制来更新堆表。Greenplum服务器在磁盘上以打包了元组的固定尺寸块的形式存储表数据。为了优化磁盘I/O,块被缓冲在内存中,直到缓存被填满并且一些块必须被挤出去为新更新的块腾出空间。当块被从缓存中挤出时,它会被写入到磁盘并且通过网络复制到镜像。因为缓冲机制,镜像上的表更新可能落后于主Segment。不过,由于事务日志也被复制,镜像会与主Segment保持一致。如果镜像被激活,激活过程会用事务提交日志中未应用的更改更新表。
当活动的主Segment不能访问其镜像时,复制会停止并且主Segment的状态会改为“Change Tracking”。主Segment会把没有被复制到镜像的更改保存在一个系统表中,等到镜像重新在线时这些更改会被复制到镜像。
Master会自动检测Segment失效并且激活镜像。失效时正在进行的事务会使用新的主Segment重新开始。根据镜像被部署在主机上的方式,数据库系统可能会被重新平衡直到原始的主Segment被恢复。例如,如果每台Segment主机有四个主Segment和四个镜像Segment,并且在一台主机上有一个Segment被激活,那台主机将有五个活动的主Segment。查询直到最后一个Segment完成其工作才算结束,因此性能可能会退化直至原始的主Segment被恢复使得系统恢复平衡。
当Greenplum数据库运行时,管理员通过运行gprecoverseg工具执行恢复。这个工具会定位失效的Segment、验证它们是否有效并且与当前活动的Segment对比事务状态以确定Segment离线期间发生的更改。gprecoverseg会与活动Segment同步更改过的数据库文件并且将该Segment重新带回到在线。
在失效期间,有必要在Segment主机上保留足够的内存和CPU资源,以允许要承担主要角色的镜像上增加的活动。为Greenplum数据库配置内存中为配置Segment主机内存提供的公式包括一个因子,它代表失效期间任一主机上的最大主Segment数量。Segment主机上的镜像布置会影响这一因子以及系统在失效时将如何应对。Segment镜像选项的讨论请见Segment镜像配置。
最佳实践
- 为所有Segment设置镜像。
- 将主Segment及其镜像放置在不同主机上以防止主机失效。
- 镜像可以放在一组单独的主机上或者主Segment所在的主机上。
- 设置监控,当主Segment失效时在系统监控应用中发送通知或者通过邮件通知。
- 即使恢复失效的Segment,使用gprecoverseg工具来恢复冗余并且让系统回到最优的平衡态。
双集群
对于一些用例,可以通过维护两个存储同样数据的Greenplum数据库集群提供额外层次的冗余。实现双集群的决定应该考虑到业务需求。
在双集群配置中为了保持数据同步,有两种推荐方法。第一种方法被称作双ETL。ETL(抽取、转换和装载)是常见的清理、转换、验证并且将数据装载到数据仓库中的常见数据仓库处理。通过双ETL,ETL处理会被以并行的方式执行两次,每个集群上一次,并且每一次都会做验证。双ETL提供了一个存有相同数据的后备集群。它还提供了在两个集群上查询数据的能力,并使得处理吞吐量翻倍。应用可以根据需要利用两个集群,还要确保ETL在两边都成功并且被验证。
维护双集群的第二种机制是备份和恢复。数据在主集群上被备份,然后备份被复制到第二个集群并且在其上恢复。备份和恢复机制比双ETL的延迟更高,但是需要开发的应用逻辑更少。对于按每天或者更低频率进行数据修改和ETL的用例,备份和恢复是理想的方案。
最佳实践
- 为了提供额外层次的冗余和额外的查询处理吞吐量,可以考虑双集群配置。
备份和恢复
推荐为Greenplum数据库进行备份,除非数据库中的数据可以很容易并且很干净地从源数据再生。备份可以防止操作错误、软件错误或者硬件错误。
gpcrondump工具在Segment之间并行地做备份,因此随着集群的硬件尺寸增长备份的尺度也会放大。
在某些情况下,增量备份可以显著地减小备份尺寸。增量备份保存所有的堆表,但是只保存从上次备份后更改过的追加优化和列存分区。如果数据库有待很多分区的大型事实表并且一段时间内修改被受限于一个或者几个分区,增量备份可以节省大量的磁盘空间。反过来,有大型的未分区事实表的数据库则不适合于增量备份。
备份策略必须考虑备份将被写到什么地方以及它们将被存放在哪里。备份可以发生在本地集群的磁盘上,但是它们不应该被永久存放在那里。如果数据库及其备份在同一种存储上,它们可能会同时丢失。备份还占据数据库存储或者操作所需的空间。在执行本地备份后,备份文件应该被拷贝到一个安全的、集群外的位置。
另一种策略是直接备份到一个NFS挂载上。如果集群中的每台主机都有一个NFS挂载,备份可以被直接写到NFS存储上。推荐使用一种可扩展的NFS方案以确保备份不会受到NFS设备的IO吞吐瓶颈限制。Dell EMC Isilon是这类方案的一个例子,并且可以与Greenplum集群一同扩展。
最后,通过本地API集成,Greenplum数据库可以把备份直接流式传送到Dell EMC Data Domain或者Veritas NetBackup企业级备份平台。
最佳实践
-
定期备份Greenplum数据库,除非能很容易地从源数据恢复数据。
-
使用gpcrondump的-s、-S、-t或者-T选项指定需要备份的方案和表。更多信息请见Greenplum数据库工具参考指南中的gpcrondump。
-
一次备份一个方案以减少pg_class表被锁定的时长。
在备份开始时,gpcrondump会在pg_class表上放置一个EXCLUSIVE锁,它会阻止对表的创建、修改或删除。在gpcrondump计算要备份的表集合期间该锁都会被持有,然后会在要备份的表上放置SHARED ACCESS锁。一旦那些表被锁定并且Segment上的备份处理启动,pg_class上的EXCLUSIVE锁就会被释放。在一个具有很多对象的数据库中,EXCLUSIVE锁会带来很大的干扰。一次备份一个方案可以减少EXCLUSIVE锁的持锁期。有较少表的备份对于选择性地恢复方案和表也更加有效,因为gpdbrestore不需要搜索整个数据库。更多信息请见备份处理和锁。
- 当对表相对较小并且备份之间只有少量追加优化或者列存分区被修改时,使用增量备份。
- 如果备份被保存在本地集群存储,在备份完成后,将文件移动到一个安全的、集群之外的位置。备份文件和数据库文件位于同一存储上可能会同时丢失。
-
如果操作系统支持直接I/O,设置gp_backup_directIO配置参数以减少备份期间的CPU使用。 更多信息请见使用直接I/O。
-
如果备份被保存到NFS挂载,使用一种可扩展的NFS方案(例如Dell EMC Isilon)以防止IO瓶颈。
检测失效的Master和Segment实例
即便系统检测到了失效并且为失效组件激活了后备,从系统失效中恢复需要系统管理员的介入。在每一种情况下,失效组件都必须被替换或者恢复,以便恢复完全的冗余。在失效组件被恢复之前,活动组件都缺少后备,并且系统可能不是以最优的方式运行。由于这些原因,有必要及时执行恢复操作。持续的系统监控和自动故障通知会通过SNMP和email确保管理员注意到失效并且采取行动。
Greenplum数据库服务器的ftsprobe子进程负责故障检测。每隔一段时间,ftsprobe会连接到所有的Segment并且扫描所有Segment和数据库进程,这个时间间隔可以用gp_fts_probe_interval配置参数设置。如果ftsprobe无法连接到一个Segment,它会在Greenplum数据库系统目录中把该Segment标记为“down”。在管理员运行gprecoverseg恢复工具之前,该Segment都会保持down的状态。
用户可以配置Greenplum数据库系统在特定数据库事件发生时触发SNMP(简单网络管理协议)以警告系统管理员或者向他/她发送email通知。设置SNMP的方法请见Greenplum数据库管理员指南中的“将SNMP用于Greenplum数据库系统”。
最佳实践
- 运行gpstate工具查看Greenplum系统的总体状态。
- 配置Greenplum数据库发送SNMP通知到用户的网络监控器。
- 在$MASTER_DATA_DIRECTORY/postgresql.conf配置文件中设置email通知,这样Greenplum系统可以在检测到关键问题时发email给管理员。
附加信息
Greenplum数据库管理员指南:- 监控Greenplum系统
- 恢复失效的Segment
- 将SNMP用于Greenplum系统
- 启用Email通知
- gpstate—查看Greenplum系统的状态
- gprecoverseg—恢复失效的Segment
- gpactivatestandby—让后备Master变成活动Master
Segment镜像配置
Segment镜像允许数据库查询在主Segment失效或者不可用时转移到备份Segment上。Pivotal要求对其支持的生产Greenplum数据库系统采用镜像。
为了确保高可用,主Segment及其镜像必须位于不同主机上。Greenplum数据库系统中的每一台主机都有相同数量的主Segment和镜像Segment。多连接主机应该在每个接口上有相同数量的主Segment和镜像Segment。这能确保所有主Segment运行时,Segment主机和网络资源的负载均衡,并且带来最多的资源承担查询处理。
当Segment变得不可用时,它位于另一台主机上的镜像Segment会变成活动的主Segment并且处理可以继续。主机上的额外负载会导致倾斜以及性能退化,但是应该能允许系统继续运行。直到所有的Segment返回结果之前,一个数据库查询并不完整,因此有一个额外的活动主Segment的主机带来的效果和在集群中每一台主机上增加一个额外的主Segment的效果相同。
在失效场景中,当没有主机上有超过一个镜像Segment承担主要Segment角色时,出现的性能退化最小。如果多个Segment或者主机失效,性能退化的程度取决于其上有最多镜像Segment承担主要Segment角色的主机。将一台主机的镜像散布在其余的主机上可以最小化任意单主机失效时的性能退化。
也有必要考虑集群对于多主机失效的容忍能力以及通过增加主机扩展集群时如何维护镜像配置。没有一种适合任意情况的理想镜像配置。
用户可以允许Greenplum数据库使用两种标准配置之一在集群中的主机上安排镜像,或者可以设计自己的镜像配置。
- 组镜像 — 每台主机镜像另一台主机的主Segment。这是gpinitsystem和gpaddmirrors的默认选择。
- 散布镜像 — 镜像散布在可用的主机上。这要求集群中的主机数大于每台主机上的Segment数。
用户可以设计一种自定义的镜像配置并且使用Greenplum的gpaddmirrors或者gpmovemirrors工具来建立该配置。
块镜像是一种自定义镜像配置,它把集群中的主机划分成相等尺寸的块并且在块内的主机上均匀地分布镜像。如果一个主Segment失效,其在同一块的另一主机上的镜像会变成活动的主Segment。如果一台Segment主机失效,在该块中其他每一台主机上的镜像Segment都会变成活动的。
下面的小节比较了组镜像、散布镜像和块镜像三种配置。
组镜像
组镜像是最容易设置的镜像配置,并且是Greenplum的默认镜像配置。组镜像的扩展代价最低,因为可以通过增加仅仅两台主机来完成扩展。在扩展之后无需移动镜像来维持镜像配置的一致性。
下面的图显示了一个在四台主机上带有八个主Segment的组镜像配置。
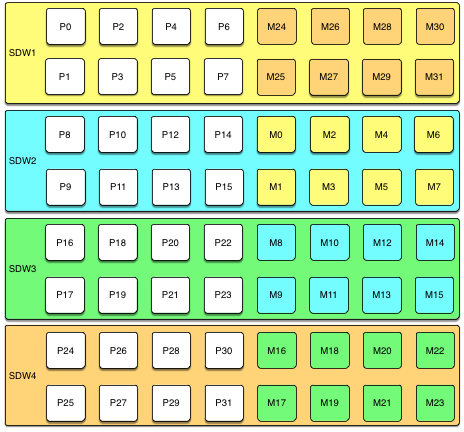
除非同一个Segment实例的主Segment和镜像都失效,最多可以有一半的主机失效并且集群将继续运行,只要资源(CPU、内存和IO)足以满足需求。
任何主机失效将会让性能退化一半以上,因为具有镜像的主机将承担两倍的活动主Segment。如果用户的资源利用通常会超过50%,用户将不得不调整其负载,直至失效主机被恢复或者替换。如果用户通常的资源利用低于50%,则集群会继续以退化的性能水平运行,直至失效被修复。
散布镜像
通过散布镜像,每台主机的主要Segment的镜像被散布在若干台主机上,涉及到的主机数量与每台主机上Segment数量相同。在集群初始化时设置散布镜像很容易,但是要求集群中的主机数至少为每台主机上的Segment数加一。
下面的图展示了一个在四台主机上有三个主Segment的集群的散布镜像配置。
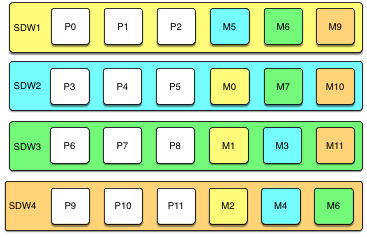
扩展使用散布镜像的集群要求更多的规划并且可能会花费更多时间。用户必须要么增加一组数量等于每台主机上主Segment数加一的主机,要么在组镜像配置中增加两个节点并且在扩展完成时移动镜像来重建散布镜像配置。
对于单主机失效,散布镜像的性能影响最小,因为每台主机的镜像都散布在最大数量的主机上。负载的增加是1/N,其中N是每台主机上主Segment的数量。不过,如果两台以上主机同时失效,散布镜像是最有可能遭受到灾难性失效的配置方案。
块镜像
对于块镜像,节点被划分成块,例如具有四台或者八台主机的块,而每台主机上Segment的镜像被放置在块中的其他主机上。根据块中主机的数量以及每台主机上主Segment的数量,每台主机会为其他每一台主机的Segment维护超过一个镜像。
下面的图展示了单块镜像配置,块中有四台主机,每台主机有八个主Segment:
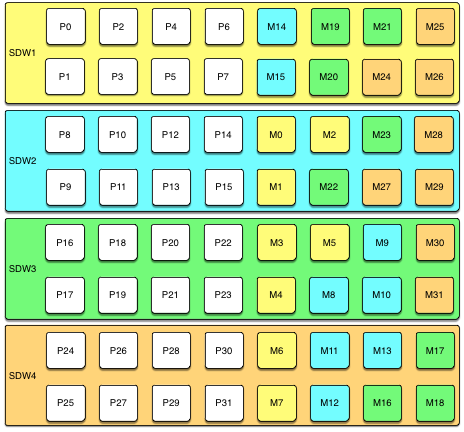
如果有八台主机,则额外增加的一个四主机块中有32至63号主Segment的镜像,其设置也是同样的模式。
使用块镜像的集群很容易扩展,因为每一个块都是一个自包含的主镜像组。集群可以通过增加一个或者多个块来扩展。扩展之后无需移动镜像来维持镜像设置的一致。只要失效的主机处于不同的块中,这种配置就能够容忍多主机失效。
因为块中的每台主机都有块中其他每台主机的多个镜像实例,对于主机失效块镜像的性能影响比散布镜像更大,但比组镜像影响要小。预期的性能影响随着块尺寸和每节点主Segment数变化。和组镜像类似,如果资源可用,性能将会受到负面的影响,但是集群仍将可用。如果资源不足以容纳增加的负载,用户必须降低负载直至失效节点被替换。
实现块镜像
在用户设置或者扩展集群时,块镜像并非Greenplum数据库提供的一种自动选项。要使用块镜像,用户必须创建自己的配置。
对于一个新的Greenplum系统,用户可以把集群初始化为没有镜像,然后用一个自定义镜像配置文件运行gpaddmirrors -i mirror_config_file来为每一个块创建镜像。在用户运行gpaddmirrors之前,用户必须为镜像Segment创建文件系统位置。详见Greenplum数据库管理工具指南中的gpadmirrors参考页。
如果用户扩展一个有块镜像的系统或者用户想要在扩展集群时实现块镜像,推荐用户先用默认的组镜像配置完成扩展,然后使用gpmovemirrors工具把镜像移到块配置中。
要在使用不同镜像方案的现有系统中实现块镜像,用户必须首先根据其块配置确定每个镜像的位置,然后确定哪些现有的镜像必须被重定位。按照下列步骤:
- 运行下列查询来查找主Segment和镜像Segment的当前位置:
SELECT dbid, content, address, port, replication_port, fselocation as datadir FROM gp_segment_configuration, pg_filespace_entry WHERE dbid=fsedbid AND content > -1 ORDER BY dbid;
gp_segment_configuration、pg_filespace以及 pg_filespace_entry系统目录表包含当前的Segment配置。
- 用当前镜像位置和想要的块镜像位置创建一个列表,然后从中移除已经在正确主机上的镜像。
- 用列表中必须要移动的每一个项(镜像)为gpmovemirrors工具创建一个输入文件。gpmovemirrors输入文件的格式如下:
filespaceOrder=[filespace1_fsname[:filespace2_fsname:...] old_address:port:fselocation new_address:port:replication_port:fselocation[:fselocation:...]
第一个非注释行必须是以filespaceOrder=开始的行。不要在文件空间列表中包括默认的pg_system文件空间。如果用户只使用pg_system文件空间,则让该列表为空。
下面的gpmovemirrors输入文件例子指定了三个要移动的镜像Segment。filespaceOrder= sdw2:50001:/data2/mirror/gpseg1 sdw3:50000:51000:/data/mirror/gpseg1 sdw2:50001:/data2/mirror/gpseg2 sdw4:50000:51000:/data/mirror/gpseg2 sdw3:50001:/data2/mirror/gpseg3 sdw1:50000:51000:/data/mirror/gpseg3
- 用下面这样的命令运行gpmovemirrors:
gpmovemirrors -i mirror_config_file
gpmovemirrors工具会验证该输入文件、调用gp_recoverseg来重定位每一个指定的镜像,并且移除原始的镜像。它会创建一个撤销配置文件,该文件可以被用作gpmovemirrors的输入来撤销所作的更改。撤销文件和输入文件同名,但会增加后缀_backout_timestamp。
关于gpmovemirrors工具的完整信息请见Greenplum数据库管理工具参考 。